
Equity Markets Quarterly Commentary Q1 2025

Cameron Gleeson
7 minutes reading time
- Technology
Related articles


Better investing starts here
Get Betashares Direct
Betashares Direct is the new investing platform designed to help you build wealth, your way.
Scan the code to download.
Learn more
Learn more
In late January DeepSeek released their R1 AI model, and for the first time US leadership in this strategically important field was challenged. In the largest single stock valuation drop ever recorded US$590B was wiped off the market value of Nvidia the next day.
While much of the Nvidia and semiconductor stock sell-off has unwound, we believe the DeepSeek breakthrough marks a new stage in AI adoption that will reset the industry landscape. Specifically, we believe that:
- The margin capture of AI hardware companies will erode over time due to model efficiency gains and increasing competition.
- Software companies that focus on delivering AI-enabled applications to consumers and corporates will be able to increase their share off the margin capture within the AI value chain.
We are already seeing early indications of this split in the year-to-date returns of the different industry groups within the S&P 500 IT sector. Hardware and Semiconductors have experienced volatility and drawdowns, whereas Software has been relatively resilient thus far in 2025.
 Source: Bloomberg, as at 14 February 2025. Industries shown are “Software”, being the S&P 500 Software & Services GICS Level 2 Industry Group, “Hardware”, is the S&P500 Technology Hardware & Equipment Services GICS Level 2 Industry Group and “Semiconductors”, is the S&P500 Semiconductors & Semiconductor Equipment GICS Level 2 Industry Group. Past Performance is not an indication of future performance. You cannot invest directly in an index.
Source: Bloomberg, as at 14 February 2025. Industries shown are “Software”, being the S&P 500 Software & Services GICS Level 2 Industry Group, “Hardware”, is the S&P500 Technology Hardware & Equipment Services GICS Level 2 Industry Group and “Semiconductors”, is the S&P500 Semiconductors & Semiconductor Equipment GICS Level 2 Industry Group. Past Performance is not an indication of future performance. You cannot invest directly in an index.
In addition, cloud platform providers will ultimately benefit from more efficient AI models through the inevitable increase in AI demand. And most importantly, end users will be able to access the benefits of this technology at a lower cost than previously expected.
The AI value chain
Ultimately AI adoption depends on the ability for this technology to deliver a productivity benefit to end users, such as consumers and ordinary businesses.
Early AI adoption by corporates looks strong. A Morgan Stanley survey found that nearly all Chief Information Officers interviewed were planning to adopt AI applications in the near future, and that more than 80% of existing AI applications have met or exceeded expectations.[1] But what is less certain is how much corporates and consumers would be willing to pay for access to AI applications on an ongoing basis. Will it be enough to cover the massive capex outlays that the hyperscalers are making? And, where will the greatest profits accrue within the AI value chain?
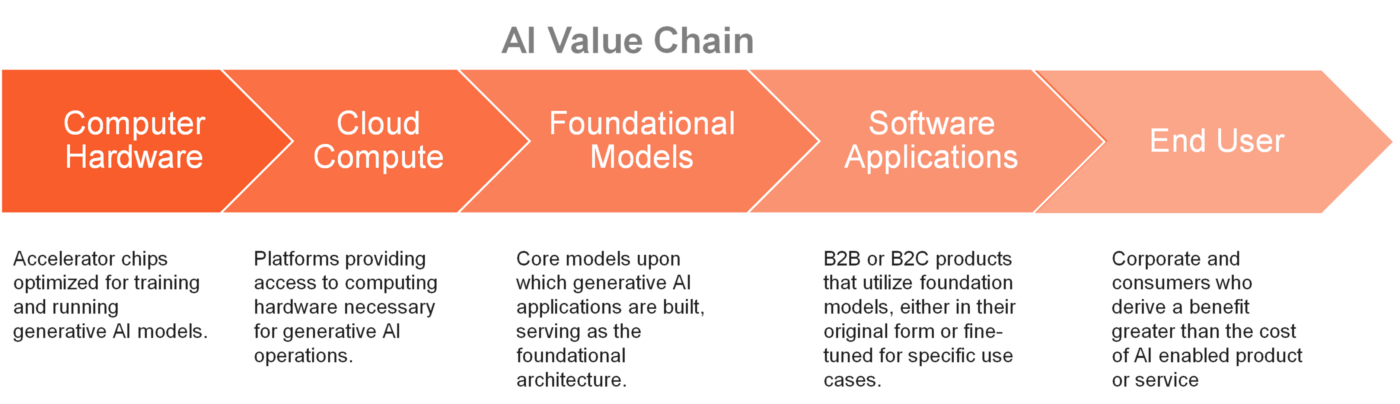
In 2023 and 2024 Nvidia sat at the apex position of the AI ecosystem, with an unassailable lead in AI hardware. Nvidia’s market share and gross margins on its leading chips both stood around 90%.
The story of Nvidia echoes that of another hardware company from the dawn of the internet age in the late 1990s – Cisco Systems. Cisco produced the best networking equipment in the market. As corporates scrambled to get on the internet, strong product margins and bullish sentiment propelled Cisco to becoming the most valuable company in the world. But in the 2000s it became clear that software (search, social, enterprise, etc) would become the dominant players in the internet age, not hardware. Cisco found it increasingly difficult to maintain product leadership in hardware as competition intensified. Whereas the scalability of software reduces the marginal cost of servicing each new customer, at the same time as network effects reinforce the moats of these businesses.
How DeepSeek changed the game
Previously the assumed path to more advanced foundational large language models (LLMs) was to increase the dataset used for training, the number of model parameters and therefore the compute required. Hence the near insatiable demand for Nvidia chips.
Then Deepseek, under export restrictions, spent only US$5.6 million to train R1 using non-market leading AI chips. This figure was roughly 1 per cent of the budget used to train OpenAI’s ChatGPT.[2]
R1 improves upon other LLM models through its ability to internally validate reasoning, to course correct answers and train itself over time. Furthermore, its Mixture-of-Experts architecture means that it selectively activates only part of the model to perform that particular task, greatly reducing the computational overhead.
The massive efficiency gains of R1’s architecture raise’s questions about whether leading AI companies are overspending on high-end Nvidia chips and cloud compute. However, DeepSeek’s breakthrough should be seen as a positive development for the AI ecosystem overall, as more efficient—and therefore cheaper—model inference will inevitably drive greater AI adoption and real-world applications.
Software versus hardware
For a clue to the potential winners and losers in AI, look to China. The “war of a hundred models” is a term used to describe the price war between numerous providers of foundational LLM models in China, which has been going on for about a year. Model providers, like Alibaba, Tencent, and DeepSeek, have cut prices to win user market share. It wasn’t just export controls on Nvidia chips that drove Deepseek to lower the computational costs of their R1 model.
This price pressure, along with availability of leading open-source model code, will likely lead to a commoditisation of foundational LLM models. For the US AI ecosystem, hardware companies are losers from this dynamic and software companies are winners.
Greater computational efficiency in foundational models will reduce demand for best-in-class chips, placing downward pressure on the margins of Nvidia and other AI hardware providers.
On the flip side, software companies will be able to develop end-user applications that utilise a choice of more efficient foundational models, and deliver those applications at a lower cost. If the Web 1.0 and 2.0 eras are any guide, the companies and platforms that are closest to the end customer in the AI value chain will win.
A great example of a software winner is Palantir Technologies. Their Foundry platform allows customers (governments and corporates) to pull together and analyse large datasets to produce insights or automate functions, utilising whichever foundational model is best suited for the task, all within a secure environment.
AI-enabled cybersecurity software, from companies like Fortinet and Palo Alto Networks, is another strong end user application for generative AI. And Meta Platforms growth in Ad revenue and share price since 2022 is evidence of their success leveraging AI with end users – both social media users and advertisers.
The hyperscalers, Amazon, Alphabet, and Microsoft, have already invested billions in proprietary closed-source LLM models, and intend to spend up to a combined US$255 billion on AI technologies and data centres this year. However this investment is not a sunk cost.
Cheaper inference cost for LLM models will inevitably result in more AI demand overall in the longer term, and therefore increasing the use of Cloud platforms for data and compute. Furthermore, the hyperscalers are also very active in terms of developing end-user applications for their customers.
Investing in AI in 2025
While the Magnificent 7 is arguably “priced for perfection[3]” in the short term, thanks to high earning growth expectations, we believe the Nasdaq 100 index provides the broadest and best exposure to AI as a theme in the long term. NDQ Nasdaq 100 ETF provides exposure not just to the Magnificent 7 but across all elements of the AI value chain, including software companies like Palantir Technologies.
Deepseek has shown the ingenuity of Chinese AI developers, in the face of US chip export controls, and that AI leadership is not America’s alone. ASIA Asia Technology Tigers ETF provides exposure to the 50 largest Asian technology companies (ex-Japan), including Chinese AI national champions, such as Tencent and Alibaba.
Cybersecurity is an example of an industry which is leveraging AI to build better software applications for its customers. HACK Global Cybersecurity ETF returned 28.26% and 19.01%pa respectively over 1- and 5-year periods to 31 January 2025. [4]
[1] AlphaWise, Morgan Stanley Research, 2024[2] There have been some that have disputed the reported US$5.6 million training budget of R1. In any case according to docsbot.ai model comparison the inference costs charged to use R1 is ~33X cheaper than that of ChatGPT4.[3] “Priced to perfection” means a stock is valued as if everything will go right, leaving little room for upside but high downside risk if expectations fall short[4] Since inception to 31 January 2025 HACK has returned 19.23%pa. Past performance is not an indicator of future performance. Total return performance is shown after ETF fees and costs as at 31 January 2025.. HACK’s returns can be expected to be more volatile than a broad global shares exposure given its concentrated sector exposure. An investment in HACK should only be considered as a small part of a broader portfolio.
Explore
Markets
1 comment on this
Cameron’s article “A changing of the guard in AI leadership”seems to suggest that because NVIDIA has such a high weightening in The ETF RBTZ(13%) .RBTZ should NOT be considered as the one of ” best exposure” even if the ETF label suggest it is . ROBOTICS and AI are a powerful market forces ! I am happy to continue to hold RBTZ in my portfolio because of its broad exposure to the AI theme.Do You agree??